模型私有化部署
结合你的云上或本地资源,完成模型平台搭建、运行链路配置和上线准备,避免“只部署不落地”。
我们为企业和团队提供从环境评估、模型平台部署到长期运维的全流程服务,重点覆盖 Linux/GPU、Kubernetes、Dify、Xinference、vLLM 等关键环节。

面向需要快速落地 AI 的团队,覆盖“搭起来、跑起来、稳下来”三个关键阶段。
结合你的云上或本地资源,完成模型平台搭建、运行链路配置和上线准备,避免“只部署不落地”。
针对业务应用进行发布、监控、容量与故障策略设置,确保服务在高峰时段依然可用。
快速定位卡顿、超时、吞吐不足等问题,输出可执行的优化方案,提升推理稳定性和成本效率。
每一步都可验证,减少沟通损耗,确保范围与结果一致。
梳理目标、现状、限制条件,明确可交付范围和里程碑。
确定架构、组件选型与部署方式,给出实施路径和风险提示。
按计划执行部署与联调,逐项验收关键节点,保证上线质量。
提供周期性巡检与问题响应,支持后续扩容和能力升级。
结合你当前阶段,可以按“实施项目”或“持续运维”两种模式合作。

从环境准备、模型服务、应用集成到监控策略,形成完整可运行的 AI 交付路径。
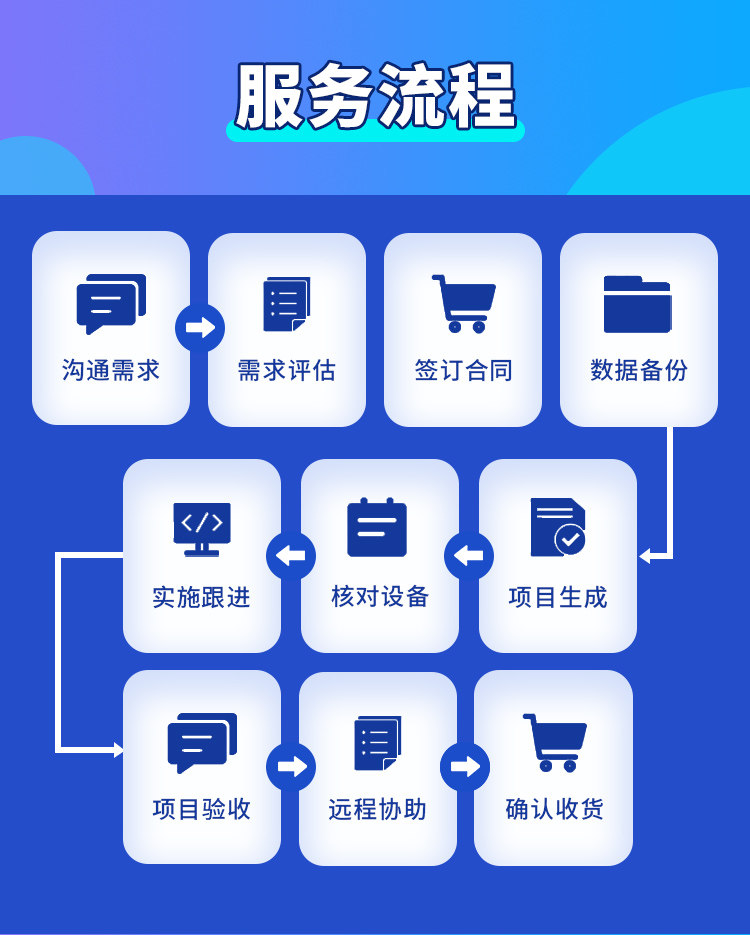
先确认边界,再逐步实施,确保每次投入都能转化为可见成果。
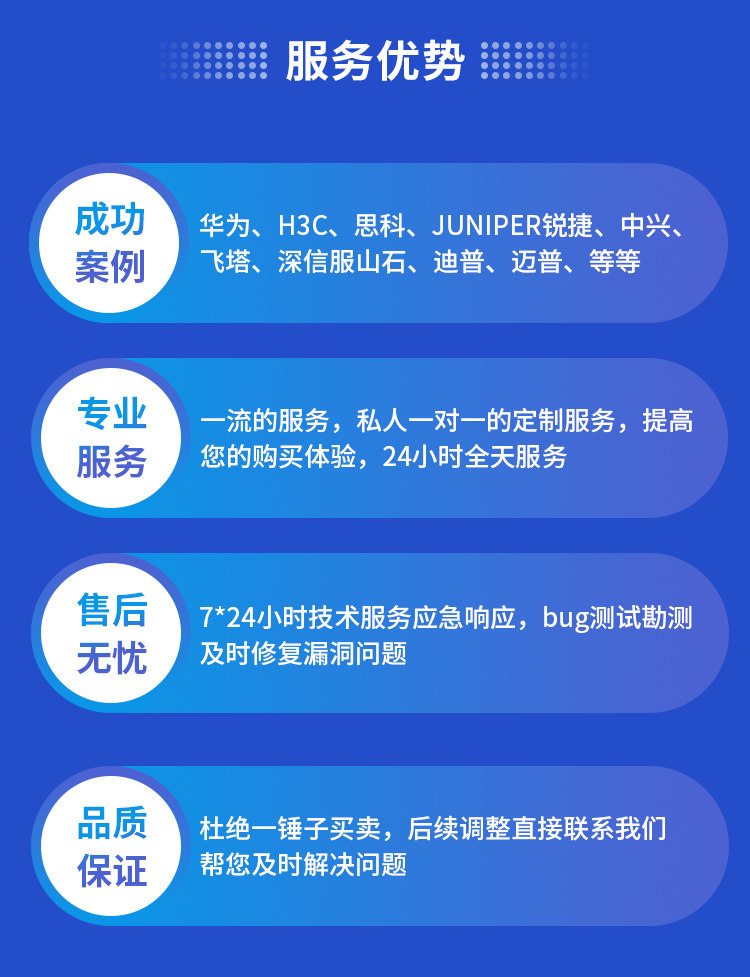
不仅关注能用,更关注持续可用,避免项目交付后无人维护。

面对突发故障和性能波动,能够快速定位并恢复服务,保障业务连续性。
如果你遇到以下情况,Aioperis 会很契合:

本服务聚焦于实施与运维支持,不包含算力资源销售与培训课程。具体内容以沟通确认及订单约定为准。
支持云上与本地环境,覆盖 Linux/GPU、Kubernetes 及常见模型服务组件。我们会在需求确认阶段给出适配建议。
两种模式都支持。可以先项目制交付,再按月或按阶段提供持续运维支持。
建议先提交需求确认,描述当前环境、目标、时间要求和期望结果,我们会快速反馈可行方案。
你可以通过淘宝店铺提交需求,或直接邮件联系。我们会先帮你把范围、风险和交付节奏说明白,再开始执行。